
티스토리 뷰
[Django/REST API] Fixtures로 TMDB API 데이터 django DB에 저장하기
meeseeks 2023. 5. 30. 12:00API 데이터를 DB에 저장하는 방법을 알아보겠습니다.
Django와 Vue로 웹 프로젝트 진행 중, TMDB Popular API 데이터를 프론트에서 요청하여 바로 사용하지 않고, Django의 DB인 SQLite에 저장하여 사용하고자 합니다.
API 데이터를 csv 등으로 정리하여 DB에 저장하는 방법도 있지만,
DB의 데이터를 JSON으로 저장하고, JSON 데이터를 DB로 불러올 수 있는 Django의 fixtures를 활용하기 위해 API 데이터를 JSON 파일로 정리합니다.
- API 데이터를 JSON형식으로 받아와, 이를 fixtures 방식으로 loaddata하려고 한다.
- 그러려면 API 데이터가 DB의 JSON구조와 일치해야한다.
- 우선 DB의 데이터들이 어떻게 JSON형식으로 저장되는지 확인해야한다.
- DB에 모델(테이블)을 정의하고, 해당 테이블에 임의의 데이터를 생성하여 dumpdata한다.
- dumpdata로 생성된 JSON 파일로 테이블의 데이터가 어떤 구조로 저장되는지 확인한다.
- API 데이터를 해당 구조에 맞춰 전처리하고, JSON 파일로 저장한다.
- 만들어진 JSON파일을 테이블로 loaddata하여 DB에 저장한다.
위 과정을 차근차근 설명해보겠습니다.
TMDB API Key 발급
TMDB API에 대한 설명이므로, 다른 API를 사용하는 경우에는 다음 과정을 생략합니다.
API를 사용하기 위해서는 API Key를 발급해야합니다.
Getting Started
Get started with the basics of the TMDB API.
developer.themoviedb.org
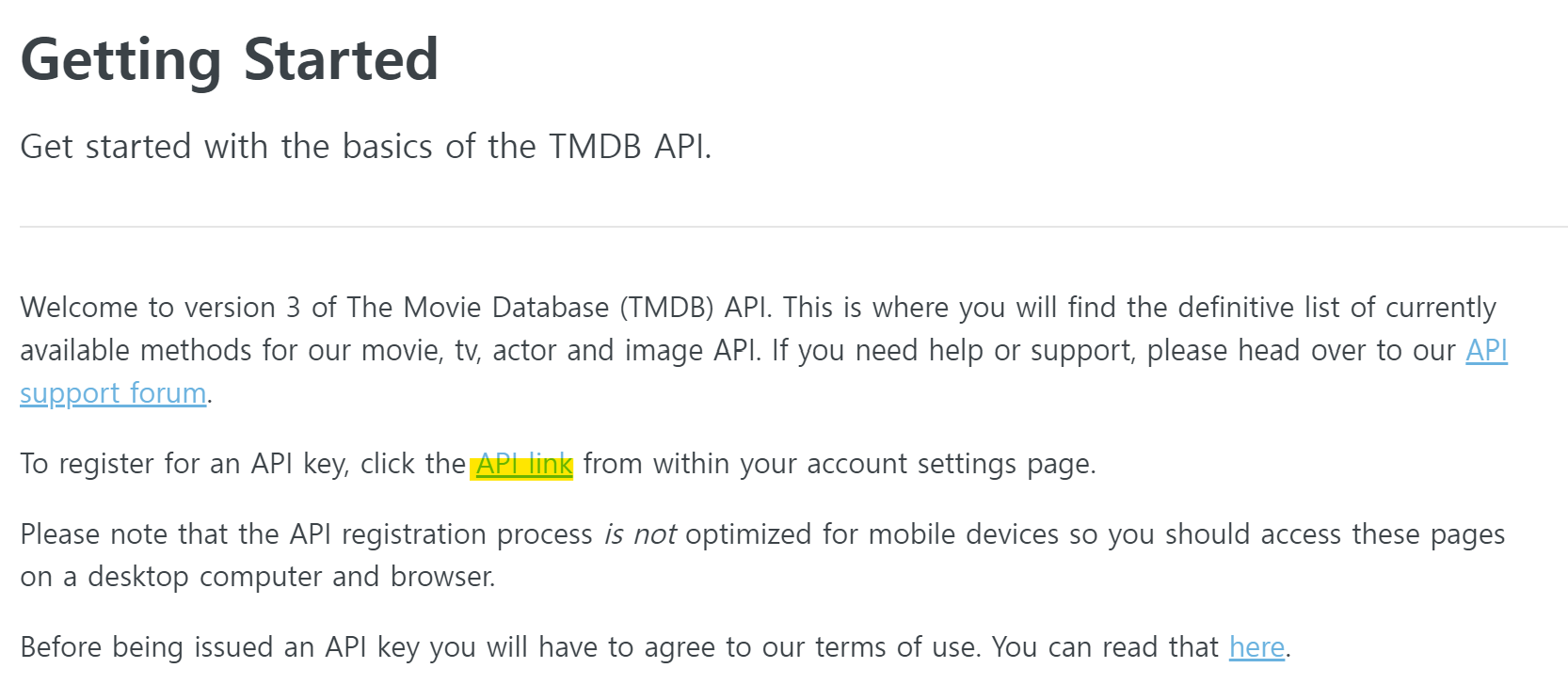
위 링크에서 TMDB 회원가입 후, API link를 클릭하여 API키를 발급받습니다.
그럼 이제 API 데이터를 받아올 준비는 마쳤습니다.
DB 테이블 생성하기
API 데이터를 저장해 줄 테이블을 먼저 생성해야합니다.
Popular
Get a list of movies ordered by popularity.
developer.themoviedb.org
API docs에서 Response를 통해 API 데이터에 어떤 필드들이 있는지 확인할 수 있습니다.
여기에서 필요한 필드만 모델에 정의해줍니다.
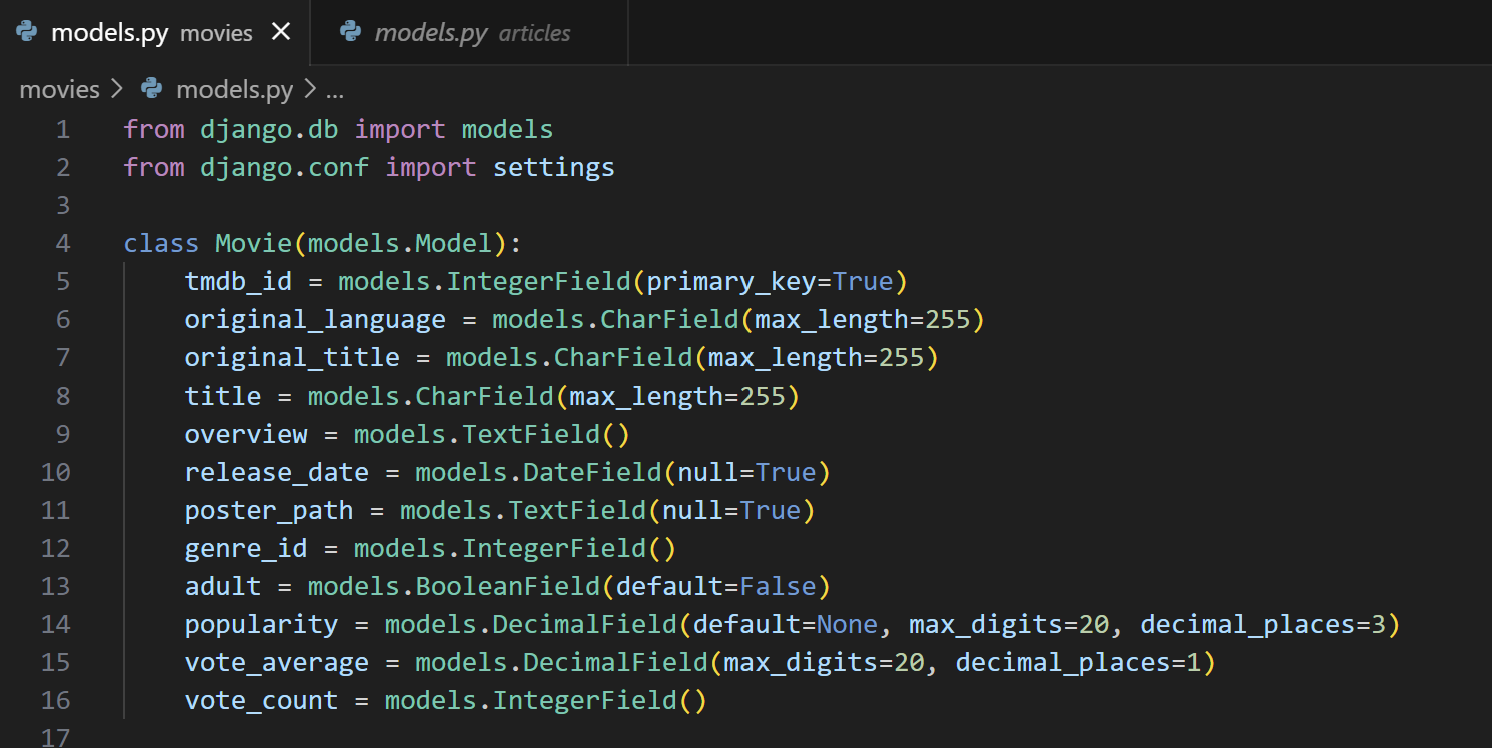
필요한 필드를 정리한 후, tmdb_id를 기본키로 하는 Movie 모델을 생성합니다.
Dummy Data 생성하기
테이블의 JSON 파일 구조를 확인하기 위해 가짜 데이터를 만들어야합니다.
총 세 가지 방법 중 하나를 선택하셔서 진행해주세요.
1. Django ORM 사용
python manage.py shellshell을 실행합니다.
from movies.models import Moviemovies 애플리케이션의 models에서 Movie 모델을 import 합니다.
movie1 = Movie.objects.create(tmdb_id=1, original_language='en', original_title='dummy movie', title='가짜 영화', overview='가짜 영화의 줄거리', release_date='2023-05-30', poster_path='assfhaiwe.jpg', genre_id='66', adult=False, popularity='123.4', vote_average='5.5', vote_count='123')
movie1.save()movie1인스턴스를 생성하고, DB에 저장합니다.
2. Django admin 사이트 사용
admin사이트에서 데이터를 생성하려면 두 가지 사전설정이 필요합니다.
첫 번째로, 모델을 정의한 애플리케이션의 admin.py에 생성한 모델을 등록합니다.
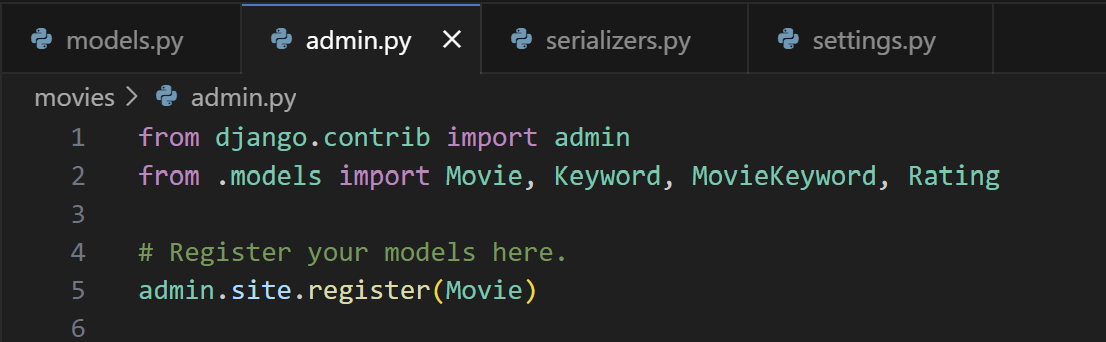
말그대로 admin site에 Movie 모델을 register합니다.
두 번째로, admin 사이트에 접근할 수 있는 관리자 계정을 생성합니다.
python manage.py createsuperuserusername과 password를 설정하면 관리자 계정이 생성됩니다.
이제 admin 사이트를 실행하여 방금 전 생성한 관리자 계정으로 로그인해줍니다.
장고의 서버를 켜고 admin/ url을 실행하면 장고에서 제공하는 기본 관리자 페이지를 사용할 수 있습니다.

관리자 계정으로 로그인하면 모든 애플리케이션의 모델들을 확인하고 데이터를 조작할 수 있습니다.
Add를 클릭하여 각 필드에 데이터를 입력하고 Save를 눌러 해당 데이터를 저장합니다.


ORM을 사용할 때보다 훨씬 간단하게 데이터를 생성할 수 있습니다.
3. django-seed 라이브러리 사용
dummy 데이터가 많이 필요하다면 django seed를 사용합니다.
JSON구조를 확인하기 위해서는 하나의 데이터만 있어도 되지만, 장고 씨드를 사용하면 빠르고 간단하게 더미 데이터를 생성할 수 있기 때문에 이 방법을 선호합니다.
django-seed 라이브러리를 설치하고 INSTALLED_APPS에 추가합니다.
pip install django-seed
django-seed를 사용하기 위해서는 psycopg 라이브러리도 함께 설치해야합니다.
pip install psycopg2
더미 데이터를 생성할 애플리케이션과 더미 데이터의 개수를 지정합니다.
python manage.py seed movies --number=20해당 애플리케이션의 모든 모델에 지정한 수의 더미 데이터가 생성됩니다.

DB에 모든 Dummy Data가 저장되었습니다.
DB 데이터의 JSON 구조 확인하기
생성한 가짜 데이터들을 dumpdata하여 Movie 모델의 fixtures 구조가 어떻게 되는지 확인합니다.
python -Xutf8 manage.py dumpdata --indent 4 movies.movie > movie_dummy.jsonmovies 애플리케이션의 movie 모델을 movie_dummy.json으로 dump합니다.
dumpdata 옵션은 다음과 같이 지정했습니다.
-Xutf8 : 한국어 데이터가 깨지지 않도록 utf8로 인코딩하여 저장
--indent 4 : JSON 파일이 보기 좋게 저장되도록 들여쓰기 지정
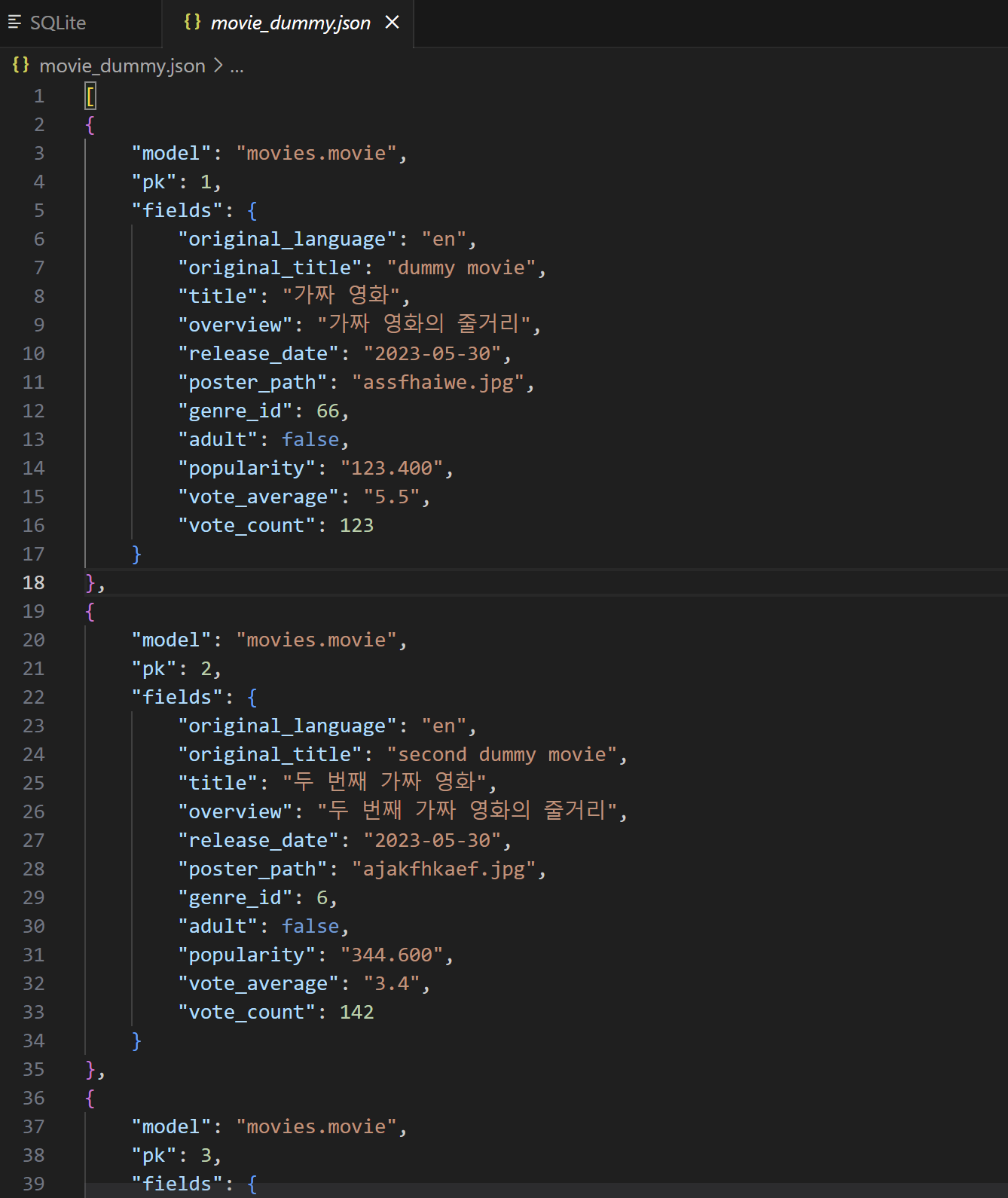
movie_dummy.json의 구조를 확인합니다.
이제 API 데이터를 위 구조와 동일하게 저장하여, DB에 loaddata할 수 있도록 합니다.
API 요청 보내서 데이터 받아오기
프로젝트 폴더 외부에 따로 데이터를 받아올 python 파일을 생성합니다.
(프로젝트 내에 생성해도 문제는 없습니다.)
import requests
import json
# TMDB API 키
api_key = 'TMDB API Key'
## Movie 모델 데이터 API 요청
# API 결과를 JSON형식으로 담을 리스트
movie_res = []
for pageNum in range(1, 501):
url = f'https://api.themoviedb.org/3/movie/popular?api_key={api_key}&language=ko-KR&page={pageNum}'
response = requests.get(url)
data = response.json()
for item in data['results']:
try:
dict = {"model" : "movies.movie",
"pk" : item['id'],
'fields': {
"original_title": item['original_title'],
"title": item['title'],
"overview": item['overview'],
"release_date": item['release_date'],
"poster_path": item['poster_path'],
"genre_id": item['genre_ids'][0],
"adult": item['adult'],
"popularity": item['popularity']
}}
movie_res.append(dict)
except:
pass
with open('movie_10000.json', "w", encoding='utf-8') as f:
json.dump(movie_res,f, ensure_ascii=False,indent=4)- TMDB 데이터를 한 페이지 당 20개의 영화 데이터가 있습니다. 총 10,000개의 데이터를 수집하기 위해 1~500페이지를 요청합니다.
- movie_dummy.json의 구조와 동일하게 데이터를 생성해줍니다. 리스트 안에 각 데이터가 딕셔너리로 저장되어 있으므로, 전체 데이터를 담아줄 movie_res 리스트를 생성하고 각 데이터를 딕셔너리로 생성합니다.
- 저장을 하다보니 개봉일이 없는(개봉 전) 영화가 있어서 오류가 발생했습니다. 따라서 try, except문을 사용해서 개봉일이 존재하는 영화만 저장하도록 해주었습니다.
- 완성된 movie_res를 movie_10000.json 파일로 저장합니다.
- 한글이 포함되어 있으므로 ascii로 저장하는 옵션을 False로 지정하고, utf-8로 인코딩합니다.
- 보기 편하도록 들여쓰기 4칸을 지정해줍니다.

딕셔너리의 key와 value는 data(response를 JSON변환한 것)에서 응답된 JSON의 구조를 파악한 후, 각 key마다 정확한 데이터를 value로 지정해주어야합니다.
API 데이터를 DB에 저장하기
생성된 movie_10000.json 파일을 movies의 fixtures 폴더에 저장해줍니다.

이전에 만들어둔 더미 데이터들을 삭제해줍니다.
저는 프로젝트 시작 단계이니 DB자체를 delete해주었습니다.
이제 DB에 movie_10000.json을 load해줍니다.
python manage.py loaddata movie_10000.json
개봉일이 존재하지 않는 영화를 제외하고, 총 9830개의 데이터가 모두 DB에 저장되었습니다.
TMDB API 뿐만 아니라, 다른 모든 API들도 같은 방식으로 DB에 저장할 수 있습니다.
'프로젝트 > Django 키우기' 카테고리의 다른 글
| [Web/Django] 15. 로그인 상태에 따라 화면 다르게 보여주기 (0) | 2023.04.18 |
|---|---|
| [Web/Django] 14. 회원정보관리 (회원가입/회원탈퇴/회원정보수정/비밀번호수정) (1) | 2023.04.18 |
| [Web/Django] 13. 로그인/로그아웃 기능 추가하기 (0) | 2023.04.17 |
| [Web/Django] 12. User 모델 생성하기 (0) | 2023.04.17 |
| [Web/Django] 11. DB에서 데이터 삭제하기 (0) | 2023.04.17 |
- Total
- Today
- Yesterday
- 프로그래머스
- re라이브러리
- hdfs
- 싸피
- 완전탐색
- SSAFY
- SQL
- 리눅스
- 스택
- 바이너리 조건
- django
- 티스토리챌린지
- 정규표현식
- 빅데이터
- 백준
- json필드
- sql대소문자
- 백준 3020
- 파이썬
- 백트래킹
- ubuntu
- 우분투
- 하둡
- Linux
- MySQL
- docker
- sql 데이터타입 변경
- 오블완
- mysql binary
- stream=true
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |