기본 다지기/BigData
[Kafka] 카프카의 기본 개념
meeseeks
2023. 8. 31. 11:48
반응형
카프카에 대한 기본적인 개념을 학습한 내용입니다.
데브원영님의 아파치 카프카 강의를 참고했습니다.
싸피 1학기 데이터 엔지니어링 스터디에서 발표자료로 사용한 글로, 설명이 생략된 부분이 있습니다.
추후 보충하거나 추가 자료를 게시하도록 하겠습니다.
카프카의 역할

소스 애플리케이션과 타겟 애플리케이션의 커플링을 약하게 하는 역할
전체적인 흐름
“프로듀서” - 데이터 → 파티셔너 → 브로커 > 파티션 > 토픽 > 레코드 → “컨슈머”
- 클러스터 : 3개 이상의 브로커로 이루어짐
소스 애플리케이션이 데이터를 수집한다.
- 쇼핑몰의 클릭로그, 은행의 결제로그 등
- 다양한 형식의 데이터를 수집 : json, csv, avro 등
소스 앱이 카프카에 데이터를 전송한다.
카프카는 ‘topic’에 데이터를 담아 queue 형태로 저장한다.
타켓 앱은 카프카에서 데이터를 가져온다.
- 로그 적재, 로그 처리 등
기존에는 소스 애플리케이션 → 타겟 애플리케이션 으로 바로 데이터를 전송했으나,
소스 app과 타겟 app이 엄청 많아지면서 데이터 전송 라인이 매우 복잡해졌다.
→ 배포와 장애에 어려움을 겪음, 데이터 포맷 내부에 변경 사항이 있을 때, 유지보수가 매우 어려움
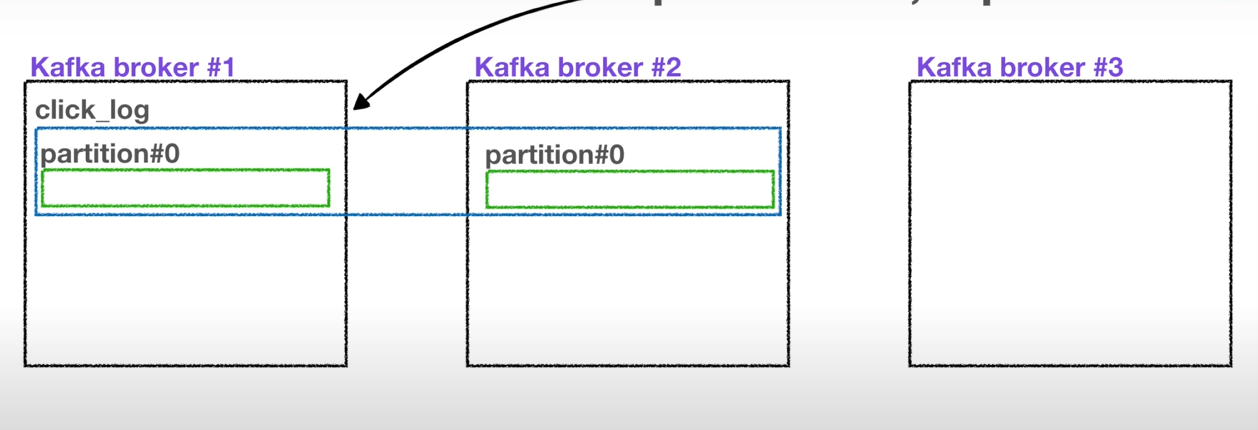
토픽?
- 카프카에서 데이터를 담는 공간
- 데이터베이스의 테이블, 파일시스템의 폴더와 비슷한 성질을 가짐.

- 프로듀서가 토픽에 데이터 넣고, 컨슈머는 토픽에서 데이터를 꺼낸다.
- 토픽의 이름을 명시하면 편하게 관리 가능
토픽의 내부

- 각 토픽은 여러 개의 파티션으로 구성되어있다.
- 파티션에 데이터를 넣고, 파티션에서 데이터를 읽는다.
- 큐 처럼 가장 먼저 넣은 값을 가장 먼저 읽는다.
- = 오래된 데이터부터 가져감
- 여러 컨슈머를 통해 데이터를 분산처리 하기 위해 파티션을 늘린다.
→ 조심해야함. 파티션은 한번 늘리면 다시 줄일 수 없다.
컨슈머가 여러 개?
- 컨슈머 A가 데이터를 0번부터 가져감
- 컨슈머 B가 데이터를 0번부터 가져감
- 동일 데이터를 여러 번 처리할 수 있다. (저장, 분석을 위한 전처리 등)
- 클릭로그 분석 및 시각화 → 엘라스틱 서치
- 클릭로그 백업 → 하둡
파티션이 여러 개?

- 키가 없으면 라운드 로빈으로 할당
*라운드 로빈 : 첫번째 값 → 첫번째 서버, 두번째 값 → 두번째 서버, 세번째 값 → 세번째 서버
- 레코드의 최대 보존 시간과 보존 크기를 지정해서 사용한다.
레플리케이션
- 파티션의 복제
- 데이터 손실을 막기위해 사용
- 원본 : 리더 파티션, 복제본 : 팔로워 파티션
- 데이터의 가용성을 높일 수 있지만 비용(디스크 사용량, 시간)이 많이 든다. 레플 몇으로 설정할지 서비스에 따라 잘 결정할 것.
- 프로듀서가 리더 파티션에 데이터 전송 ack동작
- 0 : LP에 전달 후 응답은 받지 않는다. → 속도빠르지만 유실 가능성 있다.
- 1 : LP에 전달 후 응답 받음 → 유실 가능성은 여전
- all : 1옵션 + FP에 복제가 잘 되었는지 응답받음
파티셔너
파티셔너는 데이터를 어떤 파티션에 넣을지 결정하는 역할이다.
어떤 것을 기준으로 결정할까?
→ 프로듀서가 보내는 레코드(데이터)에는 메시지가 존재한다.
이 메시지지의 키 또는 값에 따라
- 메시지 키가 있다면, 파티셔너가 해당 메시지 키를 hash값으로 변환한다.
카프카 랙
- 프로듀서가 데이터를 넣는 속도가 컨슈머가 데이터를 가져가는 속도보다 빠르다면 ?
실습
- 실제 프로젝트 환경 : AWS
- AWS EC2 인스턴스 3대 생성
- 리눅스 서버
- 주키퍼 설치 : 클러스터 운영 및 메타데이터 저장
- 카프카 설치
- 아파치 환경설정 (몇개의 파티셔너로 구성할지 등) → 여기부터 막힘
- 클러스터 === 3개의 브로커
- AWS EC2 인스턴스 3대 생성
- 내 컴퓨터로 테스트환경 구축 : 카프카 설치
WSL 설치 → 또 리눅스;
- 파이썬 라이브러리
대부분 자바 스프링을 기반으로 사용
파이썬으로 프로듀서/컨슈머 구현하여 데이터 주고받는 방법
- confluent 라이브러리
- 카프카 만든 사람이 만듦
- c로 만든 라이브러리를 호출하여 사용하는 방식
- 별도의 설치과정 필요
- kafka-python 라이브러리
- pip로 설치 가능
반응형